Behind MCM’s Ad Decision Engine
This guide explains, in plain language, how retrieval and machine learning (ML) work inside Moloco Commerce Media (MCM).
Big picture: what MCM’s ML engine actually does
Moloco Commerce Media (MCM) is an end‑to‑end platform that helps marketplaces and retailers run native ads (like Sponsored Products, Sponsored Brands, Sponsored and Reserved Display) using their own first‑party data and Moloco’s ML engine.
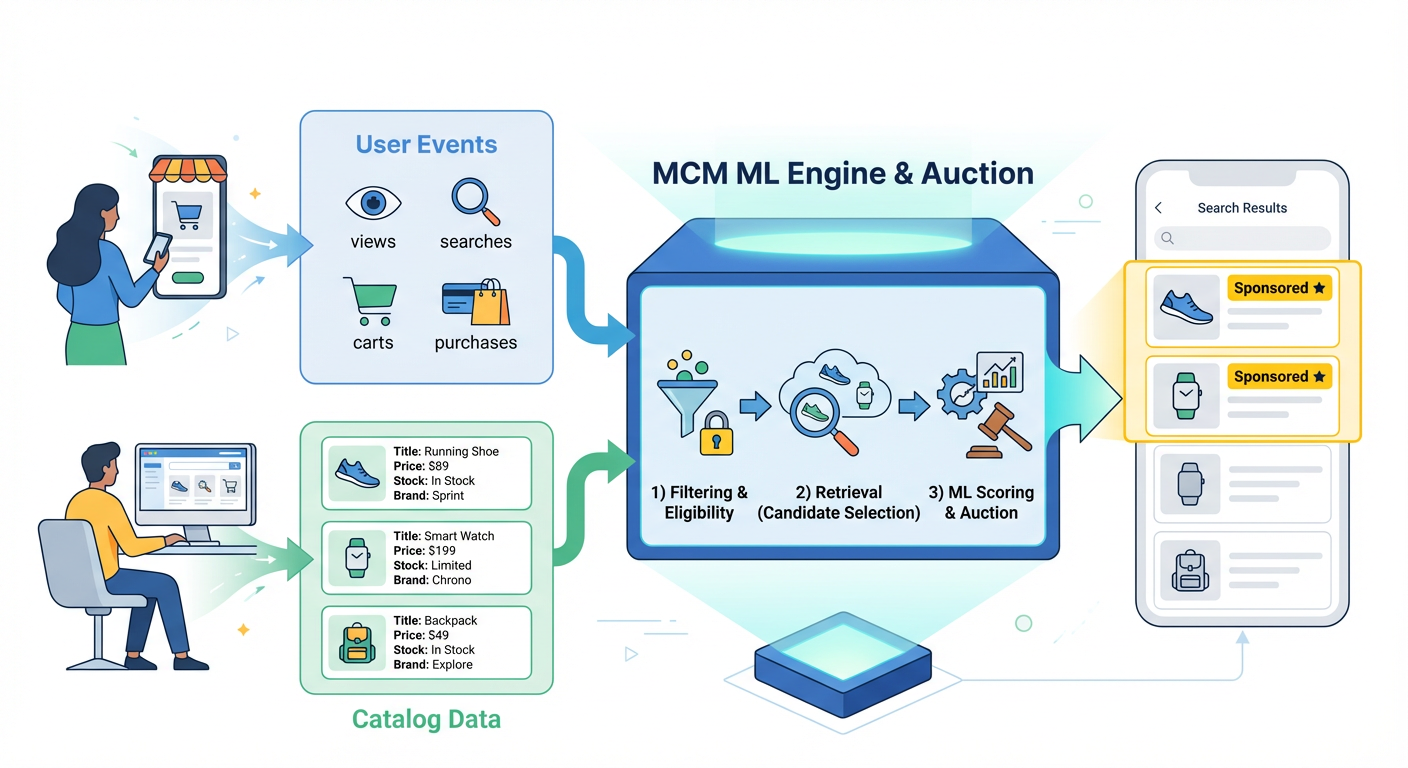
For every impression opportunity (a chance to show an ad in a specific slot), MCM needs to answer four core questions, which form a four‑layer funnel:
- Retrieval (including filtering & eligibility) – Which items can we show for this request, given all business rules, and which are the most promising candidates?
- ML scoring – Given this shopper and context, how likely is each candidate to drive a click or conversion?
- Bidding – Based on the predictions and campaign goals, how valuable is that outcome and how aggressively should each ad bid for this impression?
- Auction – Given all bids, which ads should win the available slots, in what order, and at what price?
Put another way:
- Retrieval selects a strong candidate set.
- ML scoring predicts value signals for each candidate.
- Bidding turns those signals and goals into per‑impression bids.
- Auction compares bids and finalizes winners and prices.
The ingredients: what data MCM uses
To do all this, MCM relies on three main data sources:
- Your catalog data Product titles, categories, brands, images, prices, stock, delivery options, etc. These tell the system what each item is and where it can be shown (e.g., only in certain categories, price ranges, or locations).
- Your user event data (first‑party data) Things like product page views, searches, add‑to‑cart events, purchases, and ad interactions on your site or app. These tell the system what shoppers do and like over time.
- Context for the current impression
For example:
- Which page is this? (search results, home, category page, PDP)
- What was the search query?
- What device, time of day, and location?
- Which inventory slot (top of results, middle of page, etc.)?
All of this is used by MCM’s ML engine to decide:
- “Which items are relevant to this shopper right now?”
- “How likely is the shopper to click or convert if we show this ad here?”
All ML training and prediction happen in a silo per customer. Your data is not shared across platforms; each marketplace has its own isolated ML instance.
What “retrieval” means in MCM
In an e‑commerce catalog, there can easily be hundreds of thousands or millions of items. It is too slow and expensive to run full ML scoring on every item for every impression. Retrieval solves this.
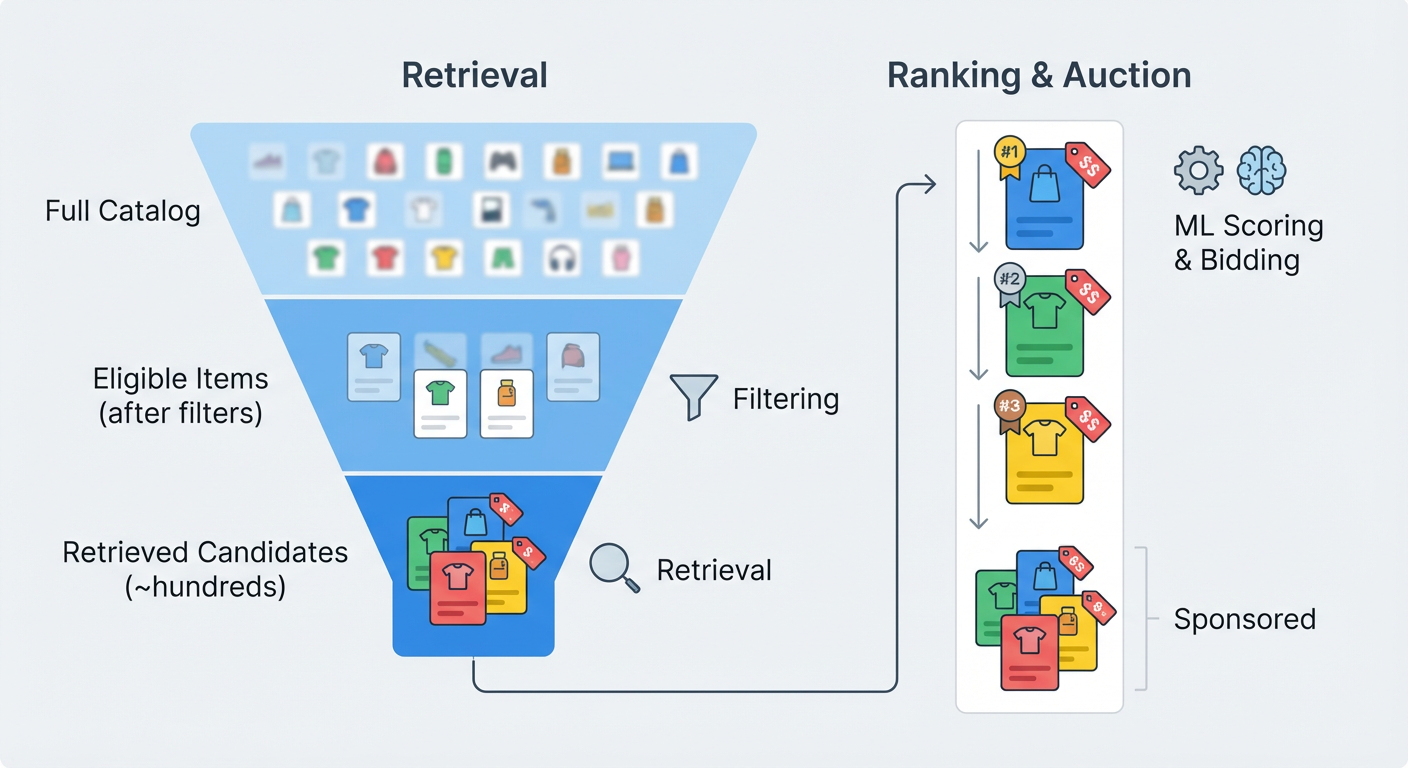
Retrieval is the ML‑powered step where MCM uses embedding/LLM‑based matching and other search strategies to quickly narrow millions of items down to a few hundred strong candidates for the later scoring, bidding, and auction stages.
What retrieval does before ML ranking
For each ad request, retrieval:
Respects filters and constraints
Only items that meet your business and campaign rules are considered, for example:
- In stock and allowed to show in this country or region
- Belong to the right category or inventory configured by the customer (e.g., “Shoes” or “Search”, “Home”)
- Come from campaigns that are active and have budget
- Match targeting rules (brand, audience segments, placements, etc.)
Uses text and behavioral signals for relevance
The system looks at fields such as:
- Title
- Categories (category tree)
- Brand
- Description
- Ad account / seller context
and combines them with:
- The shopper’s recent behavior (views, searches, purchases)
- The current page type and query (if any)
Applies multiple retrieval “strategies” in parallel
For every impression opportunity, MCM runs multiple retrieval strategies in parallel and each strategy returns a set of candidates; MCM merges and deduplicates them to form a candidate pool (typically a few hundred items).
Passes candidates to the ML ranking step
Only these retrieved candidates move forward to detailed ML scoring and auction.
How the ML engine ranks and prices ads
Once retrieval has produced a pool of eligible candidates, the ML engine decides:
- Which items have the highest change of driving clicks and conversions?
- Which items should win the slots?
- How much should each impression be worth in the auction?
- In what order should they appear?
Predicting outcomes (CTR, CVR, revenue)
For each candidate, the ML model predicts things like:
- How likely is a click? (CTR – Click‑Through Rate)
- How likely is a purchase or order? (CVR – Conversion Rate)
- What is the expected order value?
These predictions use:
- The shopper’s recent history (their “journey”)
- The item’s attributes and past performance
- The context of the page and placement
Turning predictions into bids
MCM’s bidding algorithms then combines:
- The predicted probability of success (CTR/CVR)
- The value of that success (e.g., order value)
- The advertiser’s bid strategy (Target ROAS, fixed CPC/CPM, etc.)
to compute an effective bid per impression (often called an eCPM, or “effective cost per thousand impressions”).
Bid per impression ≈(Chance of success) × (Value of success) × (How aggressive this campaign wants to be)
The auction then:
- Compares bids from all eligible ads.
- Selects the winners for each slot.
- Orders them from highest to lowest effective value and computes winning prices.
The result is that ads that are both relevant and valuable tend to win more impressions, subject to the advertiser’s budget and goals.
How ML learns over time
Machine learning is not a one‑time setup. MCM’s models continuously learn from fresh data:
- New catalog items, new creatives, price changes
- New user behavior patterns (seasonality, promotions, trends)
- Ongoing performance of campaigns (which ads actually drive conversions)
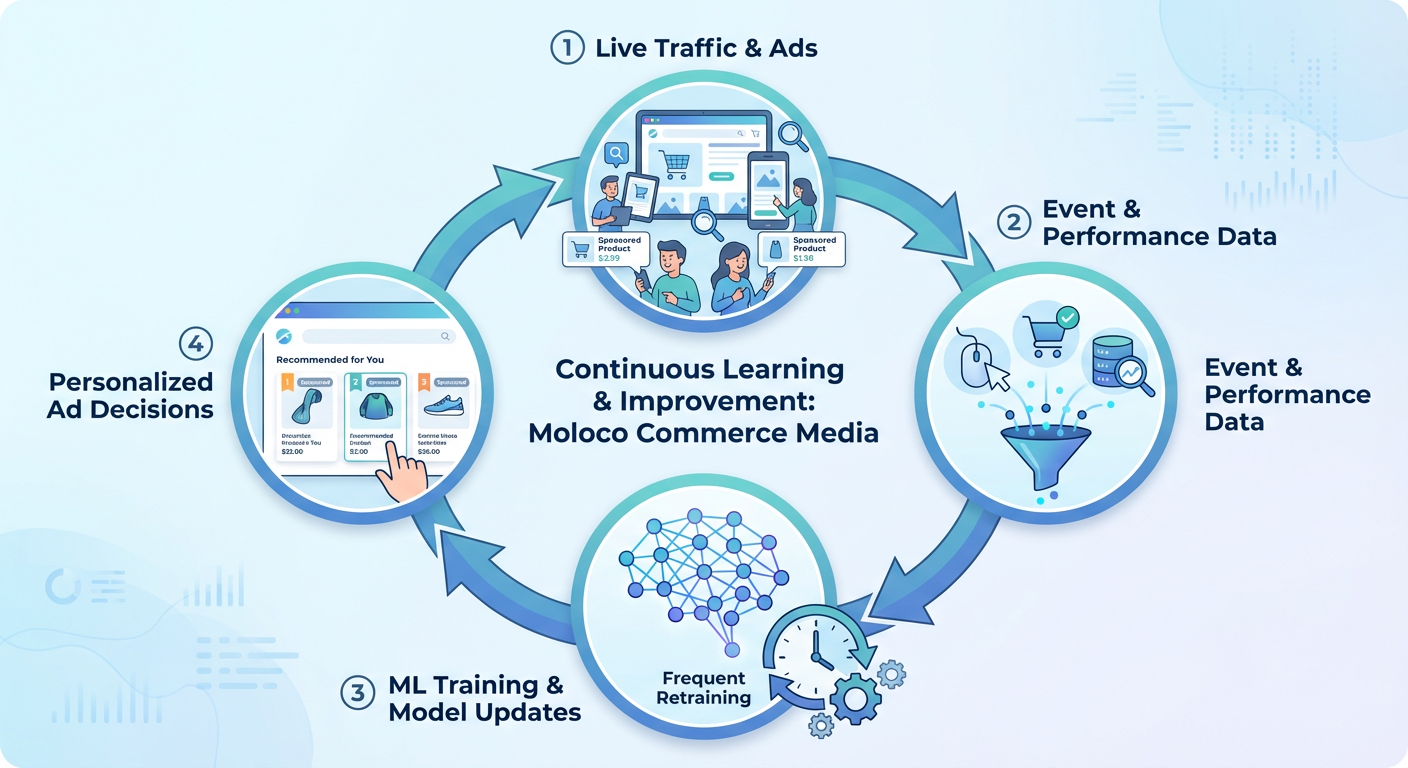
Key aspects:
Frequent retraining
MCM retrains its models regularly, so the system keeps up with changing behavior and catalog updates rather than relying on “stale” patterns.
Real‑time serving
At serving time, the model looks at the user’s current session context plus their history to personalize each impression in real time.
Continuous improvement releases
We achieve continuous performance gains by validating model improvements through rigorous online A/B experiments, ensuring each update yields measurable gains.
Per‑platform isolation
Even as we innovate on the generic ML architecture, each platform runs its own instance of the model stack, trained only on its own first‑party data, to preserve data isolation and respect privacy commitments.
Retrieval, scoring, bidding and auction: how they fit together
It’s useful to separate four different stages in your mental model:
Retrieval (including filtering rules)
- Apply inventory configuration, campaign status, budget, and eligibility constraints (stock, location, age group, etc.).
- Respect targeting (brands, categories, audiences, placements).
- Use catalog text and user behavior to fetch strong candidates.
- Run multiple strategies fast enough for real‑time serving.
ML scoring
- Predict CTR, CVR, and value‑related signals for each candidate.
- Use user history, item attributes, context, and campaign settings.
Bidding
- Combine predicted success probabilities and value with campaign goals (Target ROAS, CPC, CPM, etc.).
- Compute an effective per‑impression bid (eCPM) for each candidate.
Auction
- Compare bids across eligible ads.
- Choose winners and order them for each slot.
- Compute prices and format the final response to your ad slots.
These stages work together:
- Retrieval (with filtering inside it) ensures relevance, safety, policy compliance, and that we only send promising candidates to the expensive steps.
- ML scoring and bidding translate predicted user and business value into a concrete bid per impression.
- Auction uses those bids to maximize performance on each impression under campaign and budget constraints.
What you can do to help ML and retrieval perform better
Finally, a few very practical levers platforms can use to get more out of MCM’s ML and retrieval:
Improve catalog text fields used for relevance
- Clear, descriptive titles with brand, product type, and key attributes
- Clean categories that reflect how users browse
- Accurate brand and helpful descriptions
These fields are heavily used by MCM’s relevance and retrieval systems. For more details, follow the guide available here.
Keep filter fields accurate and consistent
- Stock, locations, business_type, age_group, gender, delivery options, etc.
- Avoid inconsistent spelling or encoding (e.g., “one_day” vs “One day”).
This helps retrieval and filtering avoid empty or poor‑quality result sets.
Send rich, reliable user events
- Page views, searches, add‑to‑cart, PDP, purchases, and ad interactions
- Correct user identifiers and timestamps
- Coverage across web and app where possible
The more complete and accurate your events, the better the ML engine can learn user preferences.
Choose clear optimization goals
- Align campaigns with business objectives (e.g., ROAS targets, sales growth, new seller activation)
- Allow enough budget and runtime for ML to explore and learn
When these inputs are strong, MCM’s retrieval and ML stack can do what it does best: serve highly relevant, performance‑driven ads that grow your commerce media business while keeping the user experience positive.
Updated 21 days ago